ChatGPTやClaudeなどの生成AIが話題を集める一方で、「もっと専門的な情報を答えてくれたら…」「社内のデータを活かせたら…」と感じたことはありませんか?
そんな悩みに応えるのが、近年、生成AIの進化とともに注目されている技術の一つである「RAG(検索拡張生成)」です。特に、社内のナレッジ共有やFAQボット構築、専門領域の情報検索などにおいて、その高い精度と実用性が注目を集めています。
この技術を使えば、生成AIに「自社のナレッジ」や「専門ドキュメント」を参照させながら、正確かつ信頼性の高い回答を出すAIシステムを作ることができます。
たとえば――
- 社内マニュアルから答えるFAQボット
- 商品カタログを理解した営業支援AI
- 医療論文をベースに回答する専門アシスタント
そんなものが、いまや個人や小規模チームでも構築できる時代になりました。
この記事では、**RAGとは何か?**から始まり、導入のための5ステップの概要を、具体的なツールや活用例とともに解説していきます。
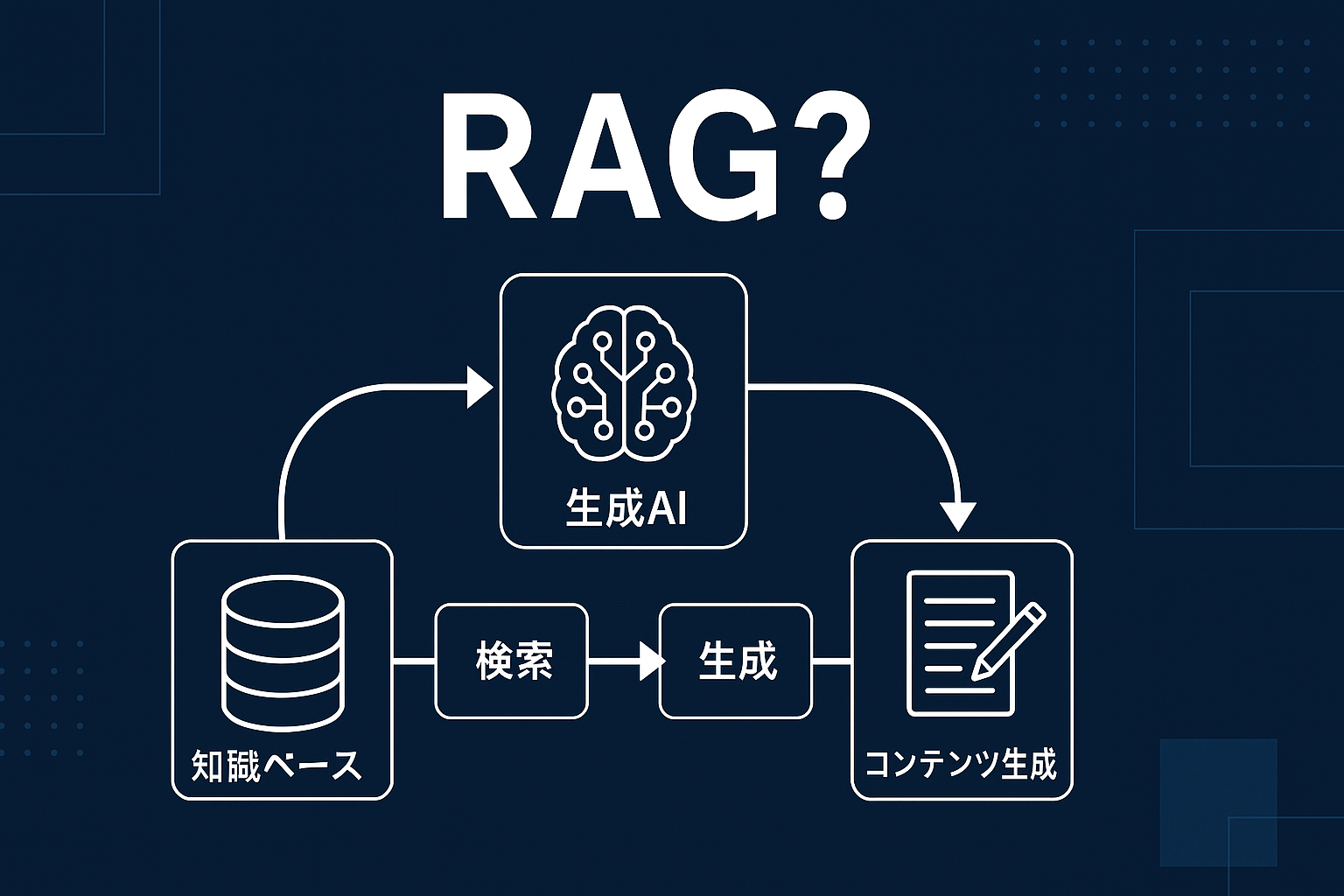
🎯 そもそもRAGとは?
**RAG(検索拡張生成)**とは、AIが回答を生成する際に、事前に学習したデータだけでなく、外部の情報(ドキュメントやナレッジベースなど)を検索して参照しながら回答を作成する仕組みです。
この仕組みは、Facebook AI(現Meta AI)が2020年に発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」によって体系化されました。
従来の生成AI(例:GPTやClaudeなど)は、あくまで事前に学習した情報に基づいて回答します。つまり、「知らないことは答えられない」もしくは「それっぽいことを言う(幻覚)」という弱点がありました。
通常の生成AIは、訓練データにない情報に対しては“幻覚(hallucination)”と呼ばれる不正確な回答をしてしまうことがあります。しかしRAGでは、次のような流れで外部情報を参照しながら、より正確な文章を生成します。
✅ RAGの基本構造
①検索(Retrieval):
ユーザーからの質問に対して、関連性の高い情報を、あらかじめ用意されたドキュメント群から探し出します。
このステップでは、AIが質問の文脈を理解し、それに合致する情報(テキスト断片=チャンク)を選び出します。キーワード一致ではなく、「意味」に基づいて情報を引き出すのが特徴です。
②生成(Generation):
検索で得られた情報をもとに、AIが自然な文章として回答を生成します。
ここでは、検索結果をそのまま出すのではなく、質問内容に応じて再構成されたわかりやすい文章として提示されます。質問が曖昧な場合も、文脈に合わせた柔軟な回答が可能です。
③コンテンツ生成(Content Generation):
回答だけでなく、応用次第ではFAQ、記事、レポート、要約などのコンテンツも自動生成可能です。
特定のトピックに関する情報を大量に保持している場合、それをもとに「人間が書いたようなコンテンツ」を自動で作ることもできます。たとえば製品ごとの特徴紹介文や、社内ナレッジの統合ドキュメントなどにも活用できます。
このように、**「知識の持ち方」ではなく「知識の引き出し方」**にフォーカスしたアーキテクチャがRAGの特徴です。
🚀 RAGを構築するための全体フロー
RAGシステムの構築は、以下の5ステップで進めることができます。
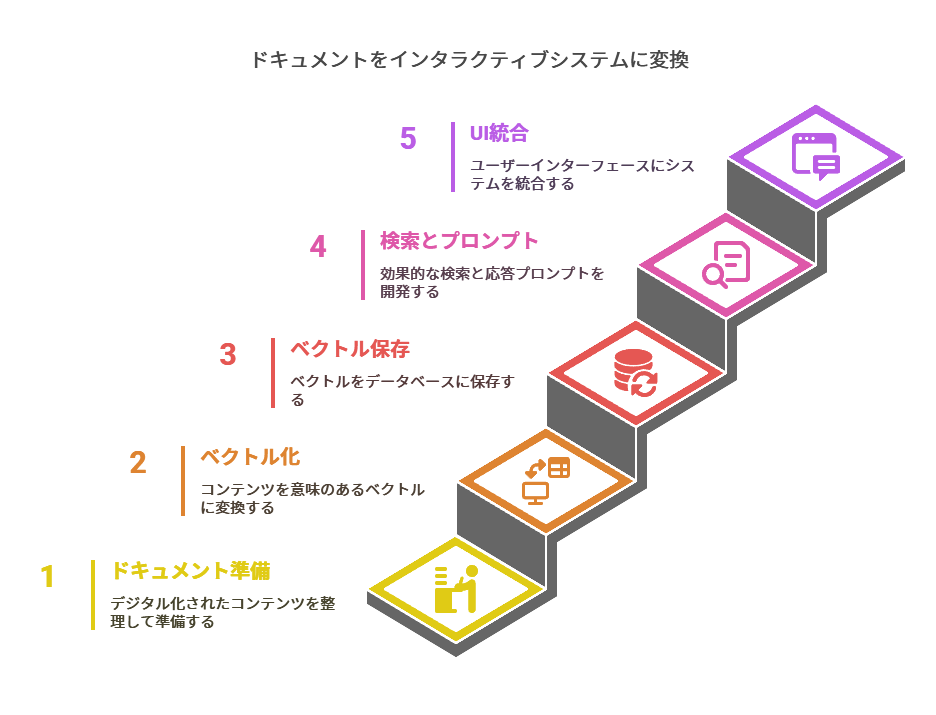
ステップ1:ドキュメント準備
ステップ2:ベクトル化(Embedding)
ステップ3:ベクトルデータベースに保存
ステップ4:検索+プロンプト構築
ステップ5:チャットUIやWebインターフェースに統合
それでは、RAGシステムを構築するための5つのステップを順を追って見ていきましょう。
✅ ①ドキュメント準備(知識ベースの整備)
RAGの土台となるのが、検索対象となるドキュメント(知識ベース)の準備です。
💡 具体的な素材の例
- 社内マニュアル(.pdf)
- 商品説明書(.txt / .md)
- Webサイトのテキスト(.csvに変換してもOK)
- 過去のQ&Aや議事録(.docxなど)
🔧 おすすめの整備方法
- ファイル形式は統一:
.txtや.pdfなど、機械処理しやすい形式にしておくとスムーズです。 - トピックごとに小分けに:長文1本より、意味ごとに分割されたドキュメントの方が精度が高まります。
✅ ②ドキュメントのベクトル化(Embedding)
RAGを理解するうえで、ちょっとハードルが高く感じるかもしれませんが、とても大事なのが、「AIが人間のように“意味”を理解して検索できる」状態をつくることです。
この状態を実現するために欠かせないのが、**Embedding(埋め込み)**と呼ばれる処理です。
🔍 Embeddingとは何か?
「Embedding」とは、テキスト(文章や単語)を、AIが扱いやすい**数値の並び(ベクトル)**に変換する技術のことです。この数値ベクトルは、ただの文字コードではなく、「意味」や「文脈」を含んだ数値空間での位置情報です。
たとえば、「りんご」と「みかん」は意味が近いので、Embedding後のベクトルも近い位置に配置されます。一方で、「りんご」と「会議室」は関係が薄いので、ベクトル空間では遠くに配置される、といった感じです。
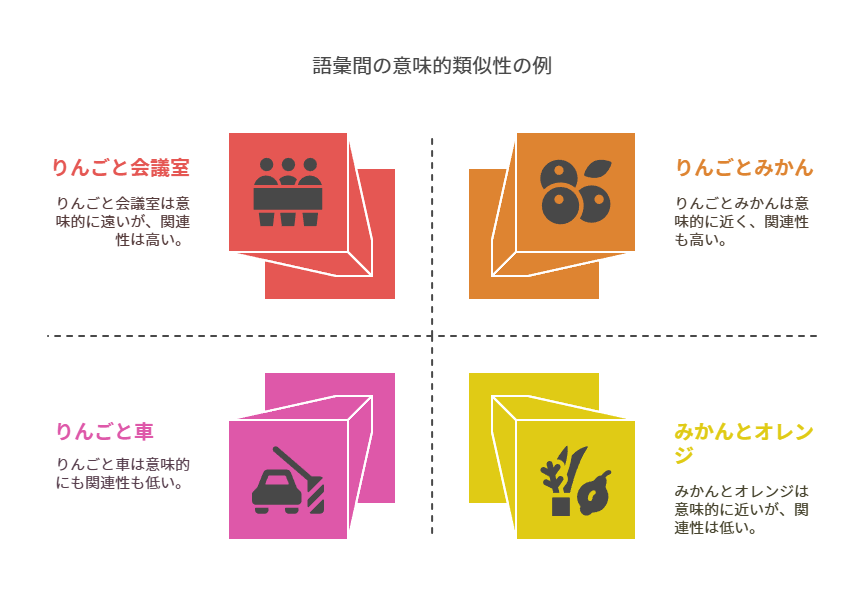
📚 なぜEmbeddingが必要なのか?
Embeddingすることで、AIは「キーワードの一致」ではなく、意味の近さに基づいた検索ができるようになります。
たとえば、ユーザーが「営業資料の作り方」と聞いたとき、文書内に「営業」「資料」「作成」という単語が直接書かれていなくても、「プレゼン資料の構成例」などが意味的に関連性が高い情報としてヒットするのです。
📚 ベクトル化は難しい? 工数は?
実は、Embeddingそのものは意外と難しくありません。
なぜなら、すでに高精度なEmbeddingモデルが用意されており、それをAPIで呼び出すだけで済むからです。
つまり、EmbeddingではAIが自動で意味に基づいて文章を分類(マッピング)してくれます。
これは素晴らしい!..パチパチ
どの文がどの話題に近いかを、AIが数値ベクトルとして自動的に整理してくれるため、人間がルールを細かく定義する必要はないわけですね。そしてその分類が適切かどうかは、実際の検索結果や生成された回答(=アウトプット)を見て判断します。
だからこそ、「読み込ませたい情報」が明確にあるなら、初心者でもRAGを活用できる可能性は非常に高いんです。
複雑な仕組みをすべて理解していなくても、まずは試してみることで、実用に近づいていくことができます。
例えば、OpenAIのEmbedding APIを使う場合は、テキストを送信するだけでベクトルが返ってきます。
コードも数行程度で済みます。Pythonが少し書ける人なら1時間以内に試せるレベルでしょう。
# OpenAIの埋め込み生成例(text-embedding-ada-002)
response = openai.Embedding.create(
input="りんごを食べたい",
model="text-embedding-ada-002"
)
embedding_vector = response['data'][0]['embedding']ノーコードツール(例:Flowiseなど)を使えば、コードを書かずにEmbedding処理を組み込むことも可能です。
このコードは、文章を「意味の座標」に変換してくれる処理を呼び出しているだけです。
しかし、何が起きてるのかピンとこないですよね…
何をやってるかをざっくり言うと…
例えば、「りんごを食べたい」という文をAIに渡すと、それを「意味の空間」にマッピングしてくれます。
イメージで言えば、AIの頭の中には“言葉の地図”みたいな空間があって、
- 「りんご」「みかん」「バナナ」などは果物ゾーンに
- 「新幹線」「電車」は乗り物ゾーンに
- 「契約」「請求」はビジネス用語ゾーンに
それぞれ位置が割り当てられています。
ベクトル化(Embedding)とは、その「意味の地図」でどこに位置しているかを、数値で表現することなんです。たとえば、AIにとってはこんなふうに見えているイメージです:
「りんごを食べたい」 → [0.13, 0.97, -0.52, ...](←果物ゾーンに近い座標)このベクトル(数値のリスト)があるからこそ、
似た意味の文が「近くにある」と判断でき、意味に基づいた検索ができるようになります。
⏱ 工数感:少数データなら数時間、本格運用は数日〜1週間
| 規模 | 工数の目安 | 備考 |
|---|---|---|
| 小規模(試作・数十文書) | 半日〜1日程度 | ノーコードやAPI利用で簡単に試せる |
| 中規模(社内マニュアルやFAQ) | 2〜3日程度 | 文書の整理・分割(チャンク化)が必要 |
| 大規模(数千〜万件のドキュメント) | 1週間〜 | バッチ処理・自動化が必要になるケースも |
ポイントは、「Embedding自体」よりも、前処理(ドキュメントの整理・分割)や後処理(検索への活用)に時間がかかることです。
🧠 RAGの検索精度を左右するカギ
Embeddingは、RAGシステム全体の中でも、検索の精度に大きく影響を与える重要なプロセスです。
このステップで使うモデルの選び方や、文書の分割方法(チャンク化)、文脈をどこまで保持するかといった工夫によって、ユーザーに返される回答の質が大きく変わります。
RAGにおける「検索精度の良し悪し」は、すなわち「Embeddingの質」にかかっている――と言っても過言ではありません。
🔧 使用ツール例
| ツール | 特徴 |
|---|---|
| OpenAI API(text-embedding-ada-002) | text-embedding-ada-002 が有名。精度・速度ともに◎ |
| Hugging Face Transformers | BERT系の日本語モデルあり。自前で運用可能 |
| Google’s Sentence-BERT(SBERT) | 英語に強いが、日本語対応モデルもあり |
このステップにより、AIが単なるキーワード一致ではなく、文脈理解による検索を可能にします。
✅ ③ベクトルデータベースに保存
Embeddingされたベクトル情報は、検索の高速化と精度向上のために**専用のベクトルデータベース(Vector DB)**に格納します。これにより、ユーザーの質問に対して類似性の高い情報を瞬時に抽出することが可能になります。
🔧 代表的なベクトルDBとその特徴
| 名前 | 特徴 |
|---|---|
| Pinecone | スケーラビリティ・速度ともに高水準。APIベースで使いやすい |
| Weaviate | オープンソース。ローカル環境でも使える柔軟さ |
| FAISS(※GitHubはこちら) | Meta製。軽量・高速・完全無料。開発者向け |
ここまでが、RAG構築における「情報の整備と検索基盤の構築」ステップになります。
✅ ④検索 & プロンプト構築
ユーザーからの質問を受け取ったら、まずは意図に沿った情報をベクトルデータベースから検索します。
このとき、検索結果として返された関連テキストをもとに、生成AIへ渡す**プロンプト(指示文)**を構築します。
🧠 重要なのは「どう聞くか」
AIはとても賢いですが、聞き方(プロンプト)次第で答えが大きく変わります。
たとえば、検索で得たテキストをそのまま渡すのではなく、
- 「以下の情報をもとに答えてください」
- 「文書にないことは推測せず『わかりません』と返してください」
- 「引用元を明記して出力してください」
などのルールを含めた構文に整えることで、回答の正確性や信頼性が一気に高まります。
🛠 検索+生成を統合するフレームワーク例
| ツール / ライブラリ | 概要 | 公式リンク |
|---|---|---|
| LangChain | Python/JavaScript対応。検索から生成までの流れを自在に組める | https://www.langchain.com/ |
| LlamaIndex(旧GPT Index) | ドキュメント管理や検索に強く、LangChainと併用しやすい | https://www.llamaindex.ai/ |
| Haystack | エンタープライズ用途向け。多言語対応(日本語もOK) | https://www.haystack.deepset.ai/ |
RAGにおける「検索〜生成」は、まさにこのステップの完成度次第。プロンプト構築の工夫が“AIの回答品質”を決める、と言っても過言ではありません。
✅ ⑤:フロントエンド or チャットインターフェースの構築
最後のステップは、ユーザーが実際にAIとやり取りできるチャットUI(ユーザーインターフェース)やアプリケーション画面を構築することです。
これはRAGシステムの中でも**ユーザーが直接触れる「見える部分」**であり、プロダクトとしての完成度や使いやすさを左右する非常に重要なフェーズです。
💬 利用される主な形
- Webチャット(例:社内ポータルや外部サービス)
- LINEボット / Slackボット
- 専用アプリや問い合わせフォームへの組み込み
🔧 よく使われる生成AI API
- ChatGPT API(OpenAI)
- Claude API(Anthropic)
- その他、Google Gemini や Cohere なども選択肢に
UIの作り方自体は自由度が高く、ノーコードで試す方法から、フルカスタムの業務ツールまで幅広く対応できます。
RAGの「フロントエンド」は、いかに使いやすく、自然にAIと接続できるかを設計する**“ユーザー体験の要”**とも言えるパートです。
まとめ
RAG(検索拡張生成)は、「検索」と「生成」を組み合わせることで、ChatGPTなどの生成AIに現実世界の知識や文脈を与える強力な手法です。
ドキュメントの整備からベクトル化、データベース構築、検索とプロンプト構築、インターフェース開発に至るまで、5つのステップを踏むことで、専門性が高く信頼性のあるAIシステムを構築することができます。
導入の規模や目的に応じて、ノーコードツールで手軽に試すことも、本格的なフレームワークで拡張することも可能です。
生成AIの次の一歩は、「どう活用するか」にあります。
RAGの仕組みを理解し、実践することで、あなた自身のAI体験を一段階アップグレードさせてみませんか?

![[GA4]キャンペーンの意味とは?レポート表示方法まで解説](https://www.ga4.odin-analytics.xyz/wp-content/uploads/2024/07/walls-io-s48GdyzvNjc-unsplash-scaled-e1721430643798-300x160.jpg)
![[GA4]初心者向け ランディングページ分析の基本と活用法](https://www.ga4.odin-analytics.xyz/wp-content/uploads/2024/07/birger-strahl-CbuF-TtHC_I-unsplash-300x169.jpg)
![[GA4]ユーザー数を正しく理解するための徹底ガイド](https://www.ga4.odin-analytics.xyz/wp-content/uploads/2024/07/disabled-toilet-548404_1280-e1720805719318-300x155.jpg)
![[GA4]セッション数の考え方の完全ガイド](https://www.ga4.odin-analytics.xyz/wp-content/uploads/2024/07/vackground-com-KTrMmadLm7w-unsplash-scaled-e1720724989395-300x152.jpg)
![[GA4]新規ユーザー数・リピーターの定義とは?](https://www.ga4.odin-analytics.xyz/wp-content/uploads/2024/07/system-2521728_1280-e1720633278566-300x159.jpg)

コメント